As you may have noticed, ILNumerics arrays implement the IEnumerable interface. This makes them compatible with ‘foreach’ loops and all the nice features of LINQ!
Consider the following example: (Dont forget to include ‘using System.Linq’ and derive your class from ILNumerics.ILMath!)
ILArray<double> A = vec(0, 10);
Console.WriteLine(String.Join(Environment.NewLine, A));
Console.WriteLine("Evens from A:");
var evens = from a in A where a % 2 == 0 select a;
Console.WriteLine(String.Join(Environment.NewLine, evens));
Console.ReadKey();
return;
Some people like the Extensions syntax more:
var evens = A.Where(a => a % 2 == 0);
I personally find both equivalently expressive.
Considerations for IEnumerable<T> on ILArray<T>
No option exist in IEnumerable<T> to specify a dimensionality. Therefore, and since ILNumerics arrays store their elements in column major order, enumerating an ILNumerics array will be done along the first dimension. Therefore, when used on a matrix, the enumerator runs along the columns:
ILArray<double> A = counter(3,4);
Console.WriteLine(A + Environment.NewLine);
Console.WriteLine("IEnumerable:");
foreach(var a in A)
Console.WriteLine(a);
Secondly, as is well known, accessing elements returned from IEnumerable<T> is only possible in a read-only manner! In order to alter elements of ILNumerics arrays, one should use the explicit API provided by our arrays. See SetValue, SetRange, A[..] = .. and GetArrayForWrite()
Lastly, performance considerations arise by excessive utilization of IEnumerable<T> in such situations, where high performance computations are desirable. ILNumerics does integrate well with IEnumerable<T> – but how well IEnumerable<T> does integrate into the memory management of ILNumerics should be investigated with help of your favorite profiler. I would suspect, most every day scenarios do work out pretty good with LINQ since it concatenates all expressions and queries and iterates the ILNumerics array only once. However, let us know your experiences!
The project aims at computations on very large distributed data sets and is intended for Azure. Interesting news for me: the library shows quite some similarities to ILNumerics. It provides array classes on top of native wrappers, utilizing MPI, PBLAS and ScaLAPACK. A runtime is deployed with the project binaries: Microsoft.Numerics, which provides all the classes described here.
‘Local’ Arrays in “Cloud Numerics”
The similarity is most obvious when comparing the array implementations: Both, ILNumerics and Cloud Numerics utilize multidimensional generic arrays. Cloud Numerics arrays all derive from Microsoft.Numerics.IArray<T> – not to be confused with ILNumerics local arrays ILArray<T> ;)!
Important properties of arrays in ILNumerics are provided by the concrete array implementation of an array A (A.Size.NumberOfElements, A.Size.NumberOfDimensions, A.Reshape, A.T for the Transpose a.s.o.). On the Cloud Numerics side, those properties are provided by the interface IArray<T>: A.NumberOfDimensions, A.NumberOfElements, A.Reshape(), A.Transpose() a.s.o).
A similar analogy is found in the element types supported by ILArray<T> and Microsoft.Numerics.IArray<T>. Both allow the regular System numeric value types, as System.Int32, System.Double and System.Single. Interestingly – both do not rely on System.Numerics.Complex as the main double precisioin complex data element type but rather implement their own for both: single precision and double precision.
Both array types support vector expansion, at least Cloud Numerics promises to do so in the next release. For now, only scalar binary operations are allowed for arrays. For an explanation of the feature it refers to NumPy rather than ILNumerics though.
Arrays Storage in “Cloud Numerics”
The similarities end when it comes to internal array storage. Both do store multidimensional arrays as one dimensional arrays internally. But Cloud Numerics stores its elements in native one dimensional arrays. They argue with the 2GB limit introduced for .NET objects and further elaborate:
Additionally, the underlying native array types in the “Cloud Numerics” runtime are sufficiently flexible that they can be easily wrapped in environments other than .NET (say Python or R) with very little additional effort.
It is hard follow that view. Out of my experience, .NET arrays are perfectly suitable for such interaction with native libraries, since at the end it is just a pointer to memory passed to thoses libs. Regarding the limit of 2GB: I assume a ‘problem size’ of more than 2GB would hardly be handled on one node. Especially a framework for distributed memory I would have expected to switch over to shared memory about at this limit at least?
In the consequence, interaction between Cloud Numerics and .NET arrays becomes somehow clumsy and – if it comes to really large datasets – with an expected performance hit (disclaimer: untested, of course).
Differences keep coming: indexing features are somehow basic in Cloud Numerics. By now, they support scalar element specification only and restrict the number of dimension specifier to be the same as the number of dimensions in the array. Therefore, subarrays seems to be impossible to work with. I will have an eye on it, if the project will support array features like A[full, end / 2 + 1] in one of the next releases
I wonder, how the memory management is done in Cloud Numerics. The library provides overloaded operators and hence faces the same problems, which have led to the sophisticated memory management in ILNumerics: if executed in tight loops, expression like
A = 0.5 * (A + A') + 0.5 * (A - A')
on ‘large’ arrays A will inevitably lead to memory pollution if run without deterministic disposal! Not to speak about (virtual) memory fragmentation and the problems introduced by heavy unmanaged resources in conjunction with .NET objects and the GC … I could not find the time to really test it live, but I am almost sure, the targeted audience with really large problem sizes somehow contradicts this approach. Unless there is some hidden mechanism in the runtime (which I doubt, because the use of ‘var’ and regular C#, hence without the option to overload the assignment operator), this could evolve to a real nuissance IMO.
Distributed Arrays
This part seems straightforward. It follows the established scheme known from MPI but offers a nicer interface to the user. Also the Cloud Numerics Runtime wraps away the overhead of cluster management, array slicing to a good extend. However, the question of memory management again arises on the distributed side as well. Since the API exposed to the user (obviously?) does not take care of disposal of temporary arrays in a timely fashion, the performance for large arrays will most likely be suffering.
As soon as I find out more details about their internal memeory management I will post them here – hopefully together with some corrections of my assumptions.
In the first part of my somehow lengthy comparison between Fortran, ILNumerics, Matlab and numpy, I gave some categorization insight into terms related to ‘performance’ and ‘language’. This part explains the setup and hopefully the results will fit in here as well (otherwise we’ll need a third part )
Prerequisites
This comparison is going to be easy and fair! This means, we will not attempt to compare an apple with the same apple, wrapped in a paper bag (like often done with the MKL) nor are we going to use specific features of an individual language/ framework – just to outperform another framework (like using datastructures which are better handled in a OOP language, lets say complicated graph structures or so).
We rather seek for an algorithm of:
Sufficient size and complexity. A simple binary function like BLAS: DAXPY is not sufficient here, since it would neglect the impact of the memory management – a very important factor in .NET.
Limited size and complexity in order to be able to implement the algorithm on all frameworks compared (in a reasonable time).
We did chose the kmeans algorithm. It only uses common array syntax, no calls to linear algebra routines (which are usually implemented in Intel’s MKL among all frameworks) and – used on reasonable data sizes – comes with sufficient complexity, computational and memory demands. That way we can measure the true performance of the framework, its array implementation and the feasibility of the mathematical syntax.
Two versions of kmeans were implemented for every framework: A ‘natural’ version which is able to be translated into all languages with minimal differences according execution cost. A second version allows for obvious optimizations to get applied to the code according the language recommendations where applicable. All ‘more clever’ optimizations are left to the corresponding compiler/interpreter.
The test setup: Acer TravelMate 8472TG, Intel Core™ i5-450M processor 2.4GHz, 3MB L3 cache, 4GB DDR3 RAM, Windows 7/64Bit. All tests were targeting the x86 platform.
ILNumerics Code
The printout of the ILNumerics variant for the kmeans algorithm is shown. The code demonstrates only obligatory features for memory management: Function and loop scoping and specific typed function parameters. For clarity, the function parameter checks and loop parameter initialization parts have been abbreviated.
public static ILRetArray<double> kMeansClust (ILInArray<double> X,
ILInArray<double> k,
int maxIterations,
bool centerInitRandom,
ILOutArray<double> outCenters) {
using (ILScope.Enter(X, k)) {
// … (abbreviated: parameter checking, center initializiation)
while (maxIterations --> 0) {
for (int i = 0; i < n; i++) {
using (ILScope.Enter()) {
ILArray<double> minDistIdx = empty();
min(sum(abs(centers - X[full,i])), minDistIdx,1).Dispose();// **
classes[i] = minDistIdx[0];
}
}
for (int i = 0; i < iK; i++) {
using (EnterScope()) {
ILArray<double> inClass = X[full,find(classes == i)];
if (inClass.IsEmpty) {
centers[full,i] = double.NaN;
} else {
centers[full,i] = mean(inClass,1);
}
}
}
if (allall(oldCenters == centers)) break;
oldCenters.a = centers.C;
}
if (!object.Equals(outCenters, null))
outCenters.a = centers;
return classes;
}
}
The algorithm iteratively assigns data points to cluster centres and recalculates the centres according to its members afterwards. The first step needs n * m * k * 3 ops, hence its effort is O(nmk). The second step only costs O(kn + mn), hence the first loop clearly dominates the algorithm. A version better taking into account available ILNumerics features, would replace the line marked with ** by the following line:
The distL1 function basically removes the need for multiple iterations over the same distance array by condensing the element subtraction, the calculation of the absolute values and its summation into one step for every centre point.
Matlab® Code
For the Matlab implementation the following code was used. Note, the existing kmeans algorithm in the stats toolbox has not been utilized, because it significantly deviates from our simple algorithm variant by more configuration options and inner functioning.
function [centers, classes] = kmeansclust (X, k, maxIterations,
centerInitRandom)
% .. (parameter checking and initialization abbreviated)
while (maxIterations > 0)
maxIterations = maxIterations - 1;
for i = 1:n
dist = centers - repmat(X(:,i),1,k); % ***
[~, minDistIdx] = min(sum(abs(dist)),[], 2);
classes(i) = minDistIdx(1);
end
for i = 1:k
inClass = X(:,classes == i);
if (isempty(inClass))
centers(:,i) = nan;
else
centers(:,i) = mean(inClass,2);
inClassDiff = inClass - repmat(centers(:,i),1,size(inClass,2));
end
end
if (all(all(oldCenters == centers)))
break;
end
oldCenters = centers;
end
Again, a version better matching the performance recommendations for the language would prevent the repmat operation and reuse the single column of X for all centres in order to calculate the difference between the centres and the current data point.
...
dist = bsxfun(@minus,centers,X(:,i));
...
FORTRAN Code
In order to match our algorithm most closely, the first FORTRAN implementation simulates the optimized bsxfun variant of Matlab and the common vector expansion in ILNumerics accordingly. The array of distances between the cluster centres and the current data point is pre-calculated for each iteration of i:
subroutine SKMEANS(X,M,N,IT,K,classes)
!USE KERNEL32
!DEC$ ATTRIBUTES DLLEXPORT::SKMEANS
! DUMMIES
INTEGER :: M,N,K,IT
DOUBLE PRECISION, INTENT(IN) :: X(M,N)
DOUBLE PRECISION, INTENT(OUT) :: classes(N)
! LOCALS
DOUBLE PRECISION,ALLOCATABLE :: centers(:,:) &
,oldCenters(:,:) &
,distances(:) &
,tmpCenter(:) &
,distArr(:,:)
DOUBLE PRECISION nan
INTEGER S, tmpArr(1)
nan = 0
nan = nan / nan
ALLOCATE(centers(M,K),oldCenters(M,K),distances(K),tmpCenter(M),distArr(M,K))
centers = X(:,1:K) ! init centers: first K data points
do
do i = 1, N ! for every sample...
do j = 1, K ! ... find its nearest cluster
distArr(:,j) = X(:,i) - centers(:,j) ! **
end do
distances(1:K) = sum(abs(distArr(1:M,1:K)),1)
tmpArr = minloc ( distances(1:K) )
classes(i) = tmpArr(1);
end do
do j = 1,K ! for every cluster
tmpCenter = 0;
S = 0;
do i = 1,N ! compute mean of all samples assigned to it
if (classes(i) == j) then
tmpCenter = tmpCenter + X(1:M,i);
S = S + 1;
end if
end do
if (S > 0) then
centers(1:M,j) = tmpCenter / S;
else
centers(1:M,j) = nan;
end if
end do
if (IT .LE. 0) then ! exit condition
exit;
end if
IT = IT - 1;
if (sum(sum(centers - oldCenters,2),1) == 0) then
exit;
end if
oldCenters = centers;
end do
DEALLOCATE(centers, oldCenters,distances,tmpCenter);
end subroutine SKMEANS
Another version of the first step was implemented which utilizes the memory accesses more efficiently. Its formulation relatively closely matches the ‘optimized’ version of ILNumerics:
...
do i = 1, N ! for every sample...
do j = 1, K ! ... find its nearest cluster
distances(j) = sum( &
abs( &
X(1:M,i) - centers(1:M,j)))
end do
tmpArr = minloc ( distances(1:K) )
classes(i) = tmpArr(1);
end do
...
numpy Code
The general variant of the kmeans algorithm in numpy is as follows:
from numpy import *
def kmeans(X,k):
n = size(X,1)
maxit = 20
centers = X[:,0:k].copy()
classes = zeros((1.,n))
oldCenters = centers.copy()
for it in range(maxit):
for i in range(n):
dist = sum(abs(centers - X[:,i,newaxis]), axis=0)
classes[0,i] = dist.argmin()
for i in range(k):
inClass = X[:,nonzero(classes == i)[1]]
if inClass.size == 0:
centers[:,i] = np.nan
else:
centers[:,i] = inClass.mean(axis=1)
if all(oldCenters == centers):
break
else:
oldCenters = centers.copy()
Since this framework showed the slowest execution speed of all implemented frameworks in the comparison (and due to my limited knowledge of numpys optimization recommendations) no improved version was sought.
Parameters
The 7 algorithms described above were all tested against the same data set of corresponding size. Test data were evenly distributed random mumbers, generated on the fly and reused for all implementations. The problem sizes m and n and the number of clusters k are varied according the following table:
min value max value fixed parameters
m 50 2000 n = 2000, k = 350
n 400 3000 m = 500, k = 350
k 10 1000 m = 500, n = 2000
By varying one value, the other variables were fixed respectively.
The results produced by all implementations were checked for identity. Each test was repeated 10 times (5 times for larger datasets) and the average of execution times were taken as test result. Minimum and maximum execution times were tracked as well.
Results
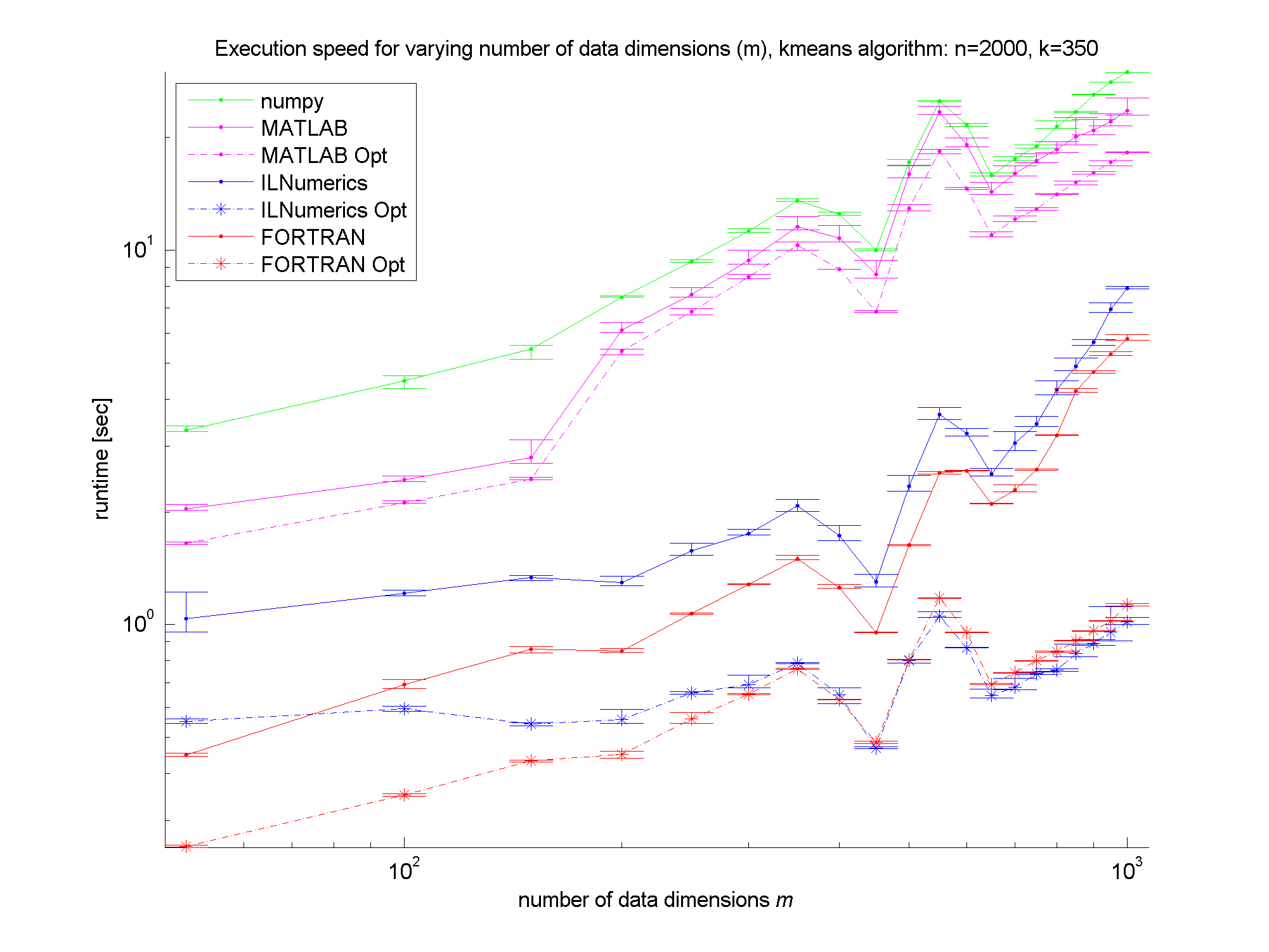
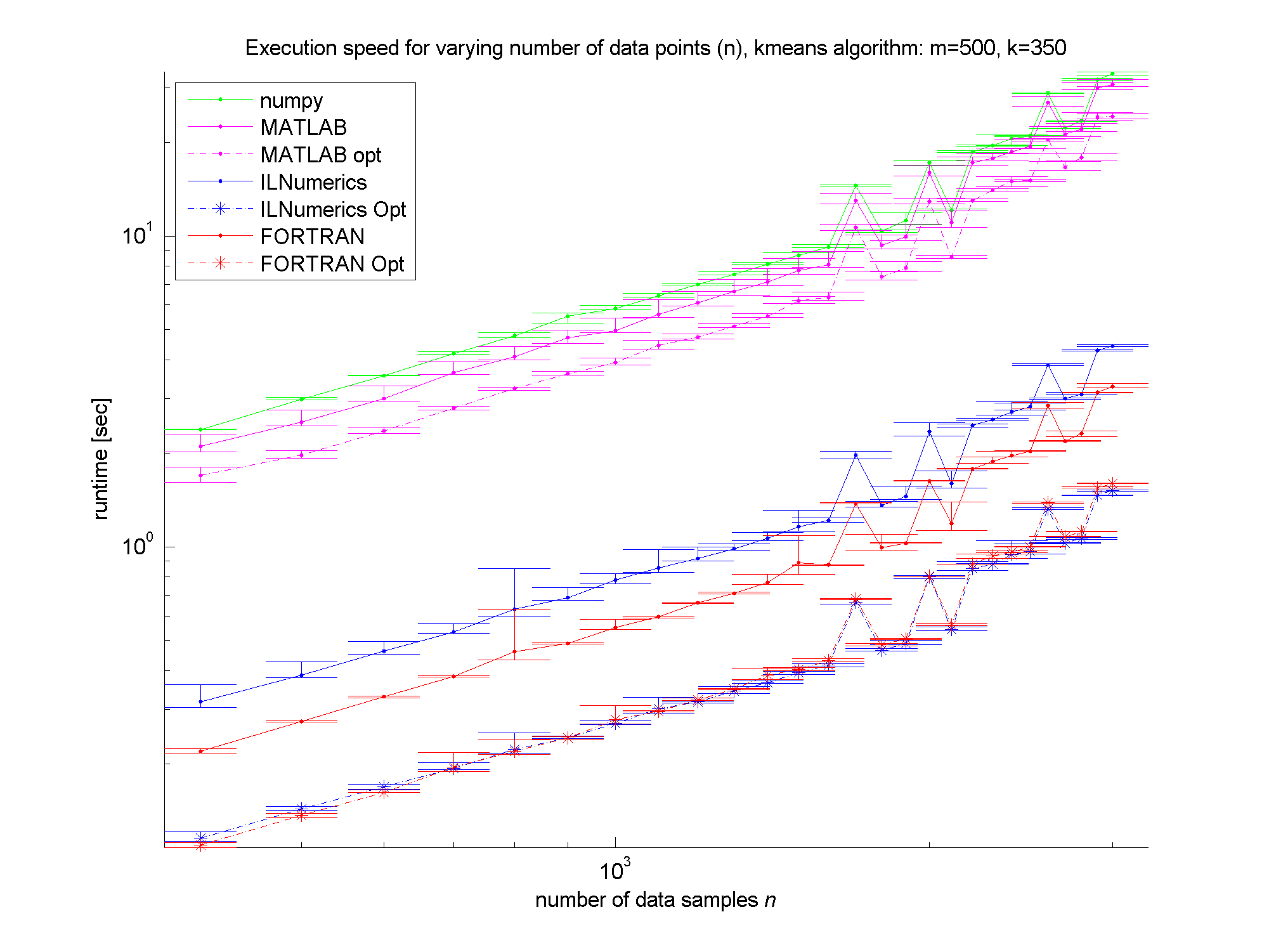
Ok, I think we make it to the results in this part! The plots first! The runtime measures are shown in the next three figures as error bar plots: Execution speed comparison for variying k Execution speed comparison for variying m Execution speed comparison for variying n
Clearly, the numpy framework showed the worst performance – at least we did not implement any optimization for this platform. MATLAB, as expected, shows similar (long) execution times. In the case of the unoptimized algorithms, the ILNumerics implementation is able to almost catch up with the execution speed of FORTRAN. Here, the .NET implementation needs less than twice the time of the first, naïve FORTRAN algorithm. The influence of the size of n is negligible, since the most ‘work’ of the algorithm is done by calculating the distances of one data point to all cluster centres. Therefore, only the dimensionality of the data and the number of clusters are important here.
Conclusion
For the optimized versions of kmeans (the stippled lines in the figures) – especially for middle sized and larger data sets (k > 200 clusters or m > 400 dimensions) – the ILNumerics implementation runs at the same speed as the FORTRAN one. This is due to ILNumerics implementing similar optimizations into its builtin functions as the FORTRAN compiler does. Also, the efforts of circumventing around the GC by the ILNumerics memory management and preventing from bound checks in inner loops pay off here. However, there is still potential for future speed-up, since SSE extensions are (yet) not utilized.
For smaller data sets, the overhead of repeated creation of ILNumerics arrays becomes more important, which will be another target for future enhancements. Clearly visible from the plots is the high importance of the choice of algorithm. By reformulating the inner working loop, a significant improvement has been achieved for all frameworks.
“Ehh..! Yet another comparison” you may say. And this is, what it is. Nevertheless, the results might be astonishing…
This post will be split in several parts. Dont know yet, how many. But at least 2. The first part will try to find a little overview or categorization of the conjunction between the terms ‘performance’ and ‘language’.
High Performance – what does it mean?
Several attempts have already been made to measure the impact the .NET CLR introduces to heavy numerical computations. Naturally, this is hard to generalize, since the final execution speed of any program does depend on so many factors. The initial language for the algorithm being only one of them. Among others are important:
the set of machine instructions presented to the CPU(s) and how the processor is able to optimize their execution
how do the compiler(s) used to get the machine code out of the higher level language are able to support the processor(s) in executing the code fast
how do the compiler(s) and/ or the high level algorithm prepare for the utilization of all available computing resources on the executing machine.
“Fast” or “high performance” languages are able to succeed in those points better than those languages, specialized for other tasks than performance. A positive example is FORTRAN, a language designed for other purposes (yet) may be found in JavaScript. At the end, the language (ie. the “features” of the language) are less important than the compilers used to generate executable code. So this is, where we get to the main difference between virtual language environments (Java, .NET and many others) and so called ‘native’ code (C/C++, FORTRAN being the most popular). While the native fraction does typically utilize one compiler to generate the final machine code in one step, the virtual fraction does introduce at least two steps. A language specific compiler generating “byte code” (‘Intermediate Language’) at development time and a Just in Time (JIT) compiler transforming that byte code into machine instructions right before the execution.
‘Virtually High’ Performance
It is a common (marketing?) argument, that the JIT compiler of a virtual machine is able to optimize the final code much better, since at runtime the actual system resources (model and number of CPU(s), cache sizes etc.) are well known. In reality, the speed of programs written for virtual machines suffer from the lack of implemented optimizations. The reason might be found in the intended audience for those environments: enterprise applications simply do not need numberchrunching performance!
Nevertheless, many attempts exist from the scientific community to utilize virtual runtime environments for numerical computing. Due to its maturity most of them aim towards Java [1],[2],[3]. Attempts for .NET just like most attempts for Java aim at providing wrapper classes in order to make the performance of ‘native’ libraries available to the higher level language. And there is nothing dubious about it. Developers writing algorithms in ‘native’ languages (lets say FORTRAN) are well advised to utilize those libraries as well. Everyone would have a hard time to beat their performance by writing – lets say – a faster matrix multiplication than the one provided by the Intel MKL (just to name one). I recently looked into exact that topic and will possibly publish those results in a later post.
So in order to categorize languages after their suitability for scientific computing, we identify the following needs:
The language should provide a ‘nice’ syntax to the user. This includes things like multidimensional arrays and overloaded operators.
There must exist tools (like compilers and/or other supporting infrastructure, possibly a library) which support the fast execution on a wide range of machines.
For a very long time, FORTRAN has been the best language according to those goals. But recent changes in the computer architecture show a significant shift in the responsibility to care about performance. While earlier, software developers commonly relied on the processor (or their designers) to run any code as fast as possible, nowadays this is over. There will be no significant improvement in a single processing unit in upcoming design cycles. Major improvements will be made by utilizing thread level performance, ie. the utilization of multicore machines and GPU power. But it will be the responsibility of the software layer now, to utilize those resources.
It wouldn’t be the ILNumerics Developer Blog, if we wouldn’t believe, that .NET and C# have very good potential to fullfill those needs – possibly better than any other major language around. In terms of the syntactic sugar the proove has been done already – simply download and try it yourself if you haven’t done yet! But ILNumerics also fullfills the second requirement! The .NET CLR as well as the mono runtime do offer several options to utilize computing resources better than other virtual machines.
Ok… but where are the plots?
In the next part I will give the results of speed measure of an every day algorithm: the k-means clustering algorithm. I have seen ‘comparisons’ on the web, where a library, utilizing the MKL compares its own matrix multiplication (carried out in the MKL) with the one from the MKL!?! Dont know, who is going to be fooled that way. We will not compare anything not executed within the virtual machine. No matrix multiplication, no linear algebra. Those parts do use optimized tools and hence run at highest possible speed anyway. K-means on the other side does only utilize array features: distance computations, binary operators, aggregate function (sum, min) etc. – all carried out within the corresponding framework.
We did choose the most popular representatives of scientific computing languages: Matlab, FORTRAN, numpy and ILNumerics and wrote the kmeans algorithm for each language twice: one time while having the best fairness in between the languages in mind and one time with major optimizations the specific language provides. Results coming in the next part…
The Productivity Machine | A fresh attempt for scientific computing | http://ilnumerics.net