ILNumerics Version 6 (beta) is out!
In version 6 of ILNumerics Ultimate VS we perform an important step: we split compatibility from performance. The new architecture allows us to bring the established ILNumerics API for computing and visualizations to all platforms supported by .NET. By the time of writing, a public beta of version 6 is out and available on nuget.org.
One great achievement for compatibility was to get over with the old installer. For years and with .NET Framework it was obligatory to install our libraries into the GAC. Further, ILNumerics did depend on many native DLLs. They came in two flavours: 32bit and 64bit. The Windows way of managing them was (and still is) to store them into special system folders. And then there was our extension to be installed into Visual Studio and the registry…. All this required administrative privileges. Together with our own code, documentation and further tools ILNumerics installer added up to more than 300 MB in size.
It worked pretty well for some time. But the .NET ecosystem changed at breakneck speed. It went open-source. It cut .NET Framework from further innovations. Packaging moved to nuget.org. Visual Studio became ‘asynch’ and changed the way to load its extensions. Some initial versions of .NET Core ultimately led into .NET 5 – to be the “single .NET” going further … It took us some time to catch up.
One problem which caused us headaches was: compatibility! With .NET Framework there was basically only one platform to support: Windows. In some cases customers used ILNumerics on Linux, too. But for years it was enough to provide a Windows – only version. And the installer kind of protected anyone from (mis)using ILNumerics on unsupported platforms.
Now, with recent developments, .NET is not Windows – only anymore! For broadest compatibility our libraries ought to target ‘.NET Standard’. For a vendor like us this means, having to support any platform, supporting .NET! Looking at various projects delivering .NET Standard libraries with native dependencies this implication seems not to have found its way onto all developer desks, yet.
“ILNumerics now runs on .NET”
We were looking for a way to enable true compatibility for ILNumerics. A way to no longer depend on native libraries! Let’s take the MKL as an example: for 40-ish years whole teams of very clever guys implement and improve linear algebra FORTRAN routines for decomposition of matrices. These algorithms are indispensable today. They mark the state of the art and are relied upon throughout all industries. Whichever alternative one may come up with – it will most likely not show the same robustness nor precision!
So, re-implementing was no option. Hence, we wrote a compiler, able to transform FORTRAN sources into equally efficient .NET code. It took us almost a year to not only translate all of LAPACK, FFTPACK and MINPACK but also all tests (>5 Mill LOC) and have them succeed.
It paid off: instead of “running on .NET, platform XX” ILNumerics now “runs on .NET”! Native libraries are only left for platform specific optimizations. They are not required anymore!
Release of version 6 is scheduled for August 2021. It will make your life much easier when it comes to referencing, updates and distributing your ILNumerics apps. And there is more in version 6, including bug fixes and new features. The documentation will be incrementally updated for the new version. The beta is online. It runs with your existing subscription (must refresh your license in Visual Studio) or with a regular trial license.
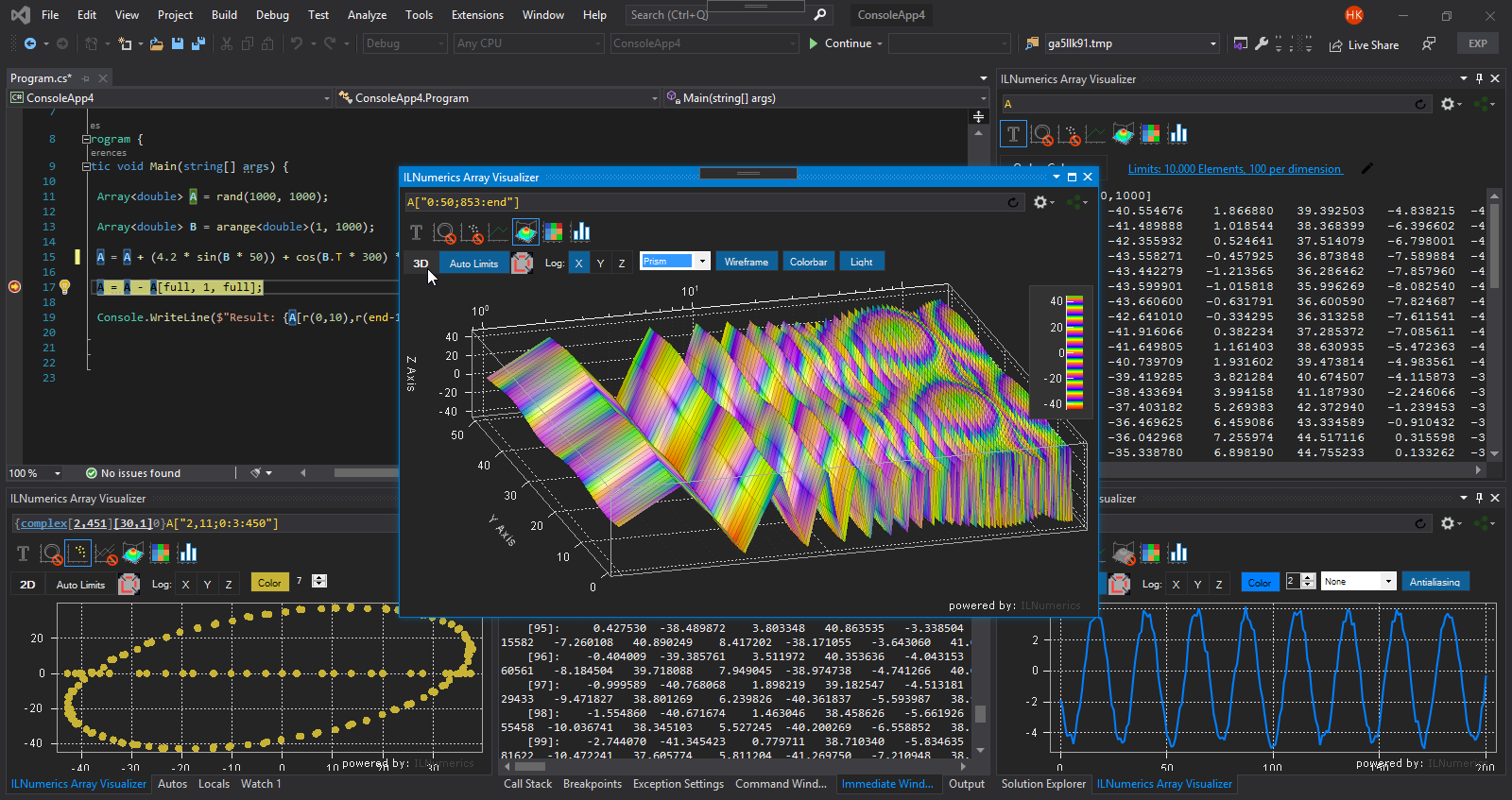
Where is the Array Visualizer?
The ILNumerics Visual Studio extension is split from the rest of ILNumerics Ultimate VS. It is published in the Marketplace and can be used free of charge. The Array Visualizer has seen a fresh-up and has been unlocked for all features, including visualizing debug memory of C,C++,FORTRAN and .NET arrays as well as plain pointers and arbitrary storage schemes. Further, the extension is required in order to manage and refresh your ILNumerics licenses on your developer seat. It supports Visual Studio from version 2017.
What to expect from Version 7?
Behind the scenes we have been very busy working on new innovations for unseen performance. And this new performance will be delivered by a purely managed solution with version 7! It will not only catch up with native compiled code on multicore processors, but instead will automatically use all suitable computing hardware found on your system. It will not require you to write any GPU code. You will not even have to decide where a certain piece of code is going to be executed on! All decisions are made only when all information is available: at runtime, automatically, by the ILNumerics Accelerator (patent pending).
Are you interested in giving this new experience a try? Let us know and join us for an early alpha test: accelerator@ilnumerics.net